
AWSを利用する際に知っておきたい障害対策
ITシステムにはシステム障害がつきもので、AWS(Amazon Web Services)も例外ではありません。実際に日本でも、過去に東京リージョンで大規模障害が発生しています。AWSで起きうる障害にはどのような種類があるのか、また、どのような設計を行えばAWSの障害によるシステム停止の影響を緩和できるのか、本記事で記載していきます。
AWSでも障害は発生する
AWSでも、何かしらの障害が発生します。2015年から2019年には、毎年1回、大規模な障害が発生しています。AWS側でも、SLA(Service Level Agreement:サービスレベル合意)を提示しており、SLA以上の稼働を保証していません。
例えば、AWSの仮想サーバサービスであるEC2は、99.99%となっています。これは、年間に換算すると、障害による52分程度の停止は許容する、ということになります。ただし、AWSにおいても正しくシステムを設計し、利用することで、障害による影響を軽減できます。例えば、NetflixはAWSで世界中にサービスを展開していますが、2015年から2019年の障害による影響をほとんどゼロにとどめています。具体的な障害の事例をみながら、どのような対策をしていけばいいのか記載していきます。
AWS障害の代表例
AWSで過去にどのような障害が発生したのか、具体例を見ていきましょう。
ap-northeast-1(東京リージョン)で生じた大規模障害(2019.8.23)
AWSの東京リージョンの内の1つのデータセンター(AZ:アベイラビリティゾーン)における冷却システムの障害により複数のサービスが停止または性能劣化が発生した事例です。冷却システムの停止により、AZ内の一部の物理サーバーの温度が許容限度を超えた結果、サーバーの電源が停止し始め、同一AZ内のEC2や他のサービスのパフォーマンス劣化なども発生しました。
日本において、キャッシュレス決済のアプリや大手ゲームアプリが使用できなくなる、という影響が出ました。
us-east(米国東部リージョン)で生じた新機能追加時と同時期のネットワーク障害により発生した障害(2015.9.20)
AWSの作業者がAmazon DynamoDBというサービスの新機能を追加しました。
しかし、AWS側の想定を大幅に上回る利用者がこの機能を利用したことと、同じ時間帯に運悪くDynamoDBに利用されている物理サーバーの一部でネットワーク障害が発生していたことも重なってしまい、大規模な障害に発展しました。DynamoDBを利用しているSQSなどのAWSサービスが利用できなくなるなどの影響を受けました。
eu-west(欧州リージョン)で発生した落雷停電によって発生した障害(2011.8.8)
eu-westにおいて、落雷により給電用の変圧器が故障し、電力の供給が停止しました。これによりEC2、EBS、RDSといったサービスが利用できなくなるといった影響が生じました。
AWSの障害を素早く検知して回復を図るスタイルズの監視、運用・保守サービスはこちら→
AWS障害に関する情報を集める
AWSが使えなくなった場合は、障害の情報を収集・把握することで、エンドユーザーへの適切な伝達が可能になります。「障害かな?」とおもったら、以下のサービスを利用し、情報収集を行うといいでしょう。
Twitterの障害アカウント
AWS側で障害を速報するTwitterアカウントを運営しており、最新情報や復旧情報が得られます。アカウント名は下記の通りで、日本語で公開されています。フォローしておくといいでしょう。
awsstatusjp:東京リージョンのみ、日本語
awsstatusjp_all:全リージョン、日本語
Dashboard表示
AWSコンソールにログインすると、右上にベルのマークがあるかと思います。これをクリックすると、「Personal Health Dashboard」というサービスにアクセスすることができます。このサービスにより、AWS全体のイベントログを確認することができます。また、実際に障害が起きていた場合は、Dashboardの「Open issue」欄に発生中の障害が表示されます。

リリースノート
速報性はないですが、AWSのブログにて障害の詳細な原因と、AWS側で実施する対策が記載されます。例えば、事例として紹介した2019.8.23のリリースノートは、こちら(https://aws.amazon.com/jp/message/56489/)の通りです。確認してみると、初版が2019.8.25と、障害から2日おくれで発表がされていますが、どのような障害だったかが詳細に記載されています。
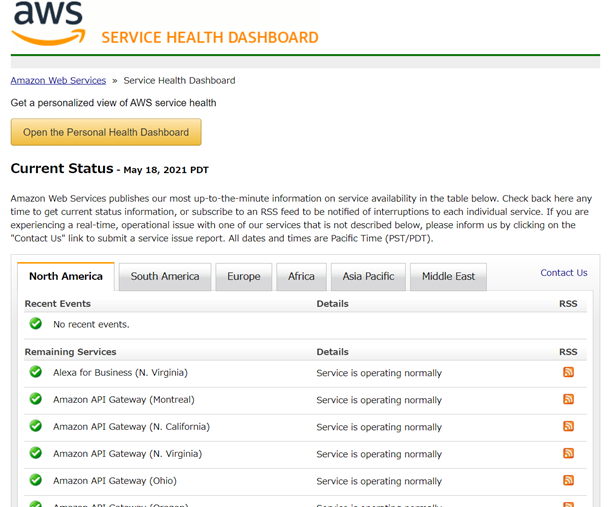
AWS Service Health Dashboard
AWSコンソールとは別に、Service Health Dashboard(https://status.aws.amazon.com/)というサイトにおいても、各サービスの稼働状況が掲載されています。こちらは、各サービスごとにRSSフィードが用意されており、RSSフィードを登録すると利用サービスの掲載内容に更新があった際には任意の方法で通知を受け取ることが可能です。
AWS障害への対策方法
AWS障害の事例や、情報収集方法を記載しましたが、原因はAWS側のオペレーションミスや、自然災害といったものになっています。AWS障害は大抵の場合、AZ単位であり、複数のリージョンが同時にダウンすることは非常にまれであることがわかります。これらを踏まえて、どのように対策を行えば影響を最小限に抑えられるか、記載していきます。
Design for Failure(障害を想定した設計)で構築する
AWSでは、単にシステム障害を回避するために設計をする、というだけでなく、万が一の障害発生の際にどの様にリカバリ出来るのかといった、障害発生時の運用の設計も非常に重要です。テスト可能な復旧手順や、AutoScalingなどの自動で復旧を行えるような仕組みを導入し、障害回避と障害復旧方法の、両方の観点でシステム設計を行うといいでしょう。
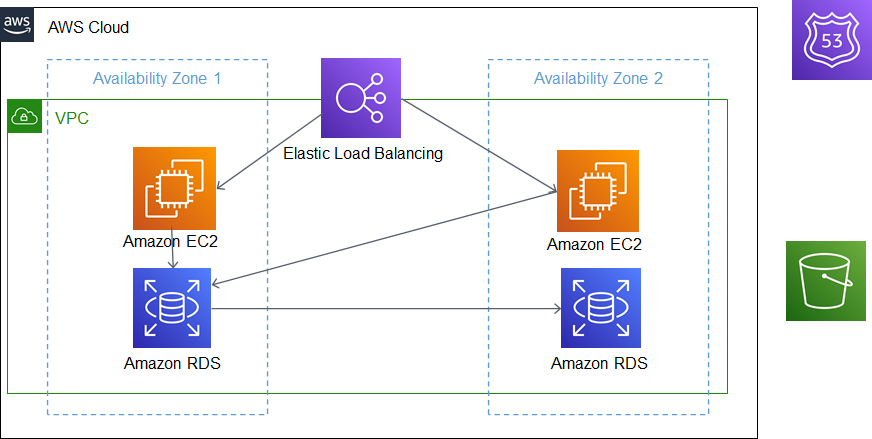
Multi-AZで運用する
EC2やRDSなどのITシステムを構成する上で、重要なリソースについては、Multi-AZ構成(複数のデータセンターをまたいでリソースを配置する構成)にするといいでしょう。先述の通り、AWSの障害はAZ単位で発生することが多いため、大抵の障害はMulti-AZ構成にしておけば影響を少なくできる、と考えることができます。
また、Multi-AZの考え方だけではなく、SPOF(Single Point Of Failure:単一障害点)をなくす、といった観点も重要です。サーバだけでなく、通信経路などにおいても、SPOFがないかを設計時点で入念に確認するといいでしょう。
意図的に障害を発生させる試験を実施する
カオスエンジニアリングという言葉をご存じでしょうか。動画配信大手のNetflixが実用化した概念で、『本番稼働中のサービスにランダムで障害を起こし、システム障害からの復旧手順を確認・確立する』というITサービスの運用手法のことです。
日々発生する障害に対応することで、障害対応のナレッジ蓄積や手順の確認を行い、大規模な障害が発生してもITサービスを止めることなくシステム運用を続けることに貢献できます。Netflixではカオスエンジニアリングを本番環境に導入し、毎日意図的に障害を発生させながら、運用の品質を高めています。
カオスエンジニアリングは、今まではオープンソースのツールを使うしかなかったのですが、2020年12月に『AWS Fault Injection Simulator』という新サービスがリリース予定であることがAWSより発表され、より手軽にカオスエンジニアリングを導入できるようになりました。
AWSの障害を素早く検知して回復を図るスタイルズの監視、運用・保守サービスはこちら→
まとめ
近年、AWSの利用が様々な企業で増加していますが、AWSも従来のITシステムと同様、障害により停止する可能性が十分にあります。障害を回避するためには、できるだけ障害を回避できるような設計や、運用を考えて利用しましょう。
また、不安なときは、設計から運用までワンストップで考慮が可能なベンダーに発注し、AWSにおけるITシステム開発のサポートを受けるといいでしょう。